
浅析403bypass
前言:本文简单的总结一下一些403bypass的绕过姿势
403的成因
- 某些敏感的URL路径配置为不允许访问
- 网络安全设备(如入侵检测系统或防火墙)可能会基于请求的特征或内容进行拦截,从而导致 403 错误
- 服务器配置成了只允许工作区的公网出口地址访问
- 服务器配置成了只允许某些特定的UA访问
- 服务器配置成了只允许某些特定的来源访问
- 因为在进行某些攻击活动,被检测到了,IP被ban
- 短时间内同一个IP过多地访问,被墙了
- 以HTTP协议访问需要HTTPS的站点
- 虽然域名的 DNS 解析记录已经设置了正确的 IP 地址,但是服务器在该 IP 地址上没有针对该域名的配置或绑定
- 服务器配置为了不允许使用IP地址访问,只能使用域名
- 上传的网页脚本文件在当前目录下没有执行权限
- 在不允许写/创建文件的目录中执行了创建/写文件操作
- 如果服务器对跨源请求进行了限制,而请求没有适当的 CORS 头部,可能会导致访问被拒绝
- DNS解析错误,手动更改DNS服务器地址
- 浏览器不支持SSL 128时访问SSL 128的连接
403绕过姿势
请求方式绕过
有些时候由于后端代码的疏忽,仅仅只对GET/POST请求做了访问控制,可以尝试FUZZ请求方式,试试看能不能绕过
1 | GET |
UA绕过
有的应用为了区分爬虫或者正常请求,会验证user-agent,伪造一个正常浏览器的UA头就可以绕过了
1 | Chrome |
客户端IP绕过
如果服务器基于客户端IP做检测与访问控制,那么我们完全可以伪造客户端IP来绕过
1 | X-Originating-IP: 127.0.0.1 |
Referer绕过
有时网站限制了访问来源,如果访问来源不符合,则也会返回403
设置referer为访问网站的host就行
url覆盖绕过
基本概念
- **
X-Original-URL**:记录请求的原始 URL。通常由代理服务器添加。 - **
X-Rewrite-URL**:记录实际请求的 URL,通常用于重写请求路径。
绕过 403 错误的原理
- 原始 URL 的访问控制:
- 服务器可以基于原始请求 URL 的路径(
X-Original-URL)来进行访问控制。 - 如果路径被配置为受限(如
/admin),某些用户可能会被禁止访问。
- 服务器可以基于原始请求 URL 的路径(
- 请求路径重写:
- 当请求经过代理或负载均衡器时,实际的请求 URL 可能会被重写。例如,将请求路径从
/user重写为/admin。 - 代理或负载均衡器可能会保留原始 URL(通过
X-Original-URL)以供后续处理。
- 当请求经过代理或负载均衡器时,实际的请求 URL 可能会被重写。例如,将请求路径从
- 利用标头绕过限制:
- 如果服务器在处理请求时检查
X-Original-URL标头,而不是实际的请求路径,那么攻击者可以伪造X-Original-URL标头来尝试访问受限资源。 - 例如:假设
/admin路径受限,只允许某些用户访问。攻击者可以发起请求并伪造X-Original-URL为/admin,从而绕过限制。
- 如果服务器在处理请求时检查
示例
- 正常访问控制:
- 用户访问
/public,代理重写为/admin。 - 服务器检查
X-Original-URL为/admin,由于访问控制限制,返回 403 错误。
- 用户访问
- 绕过访问控制:
- 攻击者伪造
X-Original-URL为/admin,发送请求。 - 如果服务器在验证访问权限时只依赖
X-Original-URL,而不是实际的请求路径,攻击者可能会绕过访问控制并访问/admin,从而得到未授权的访问。
- 攻击者伪造
1 | GET / |
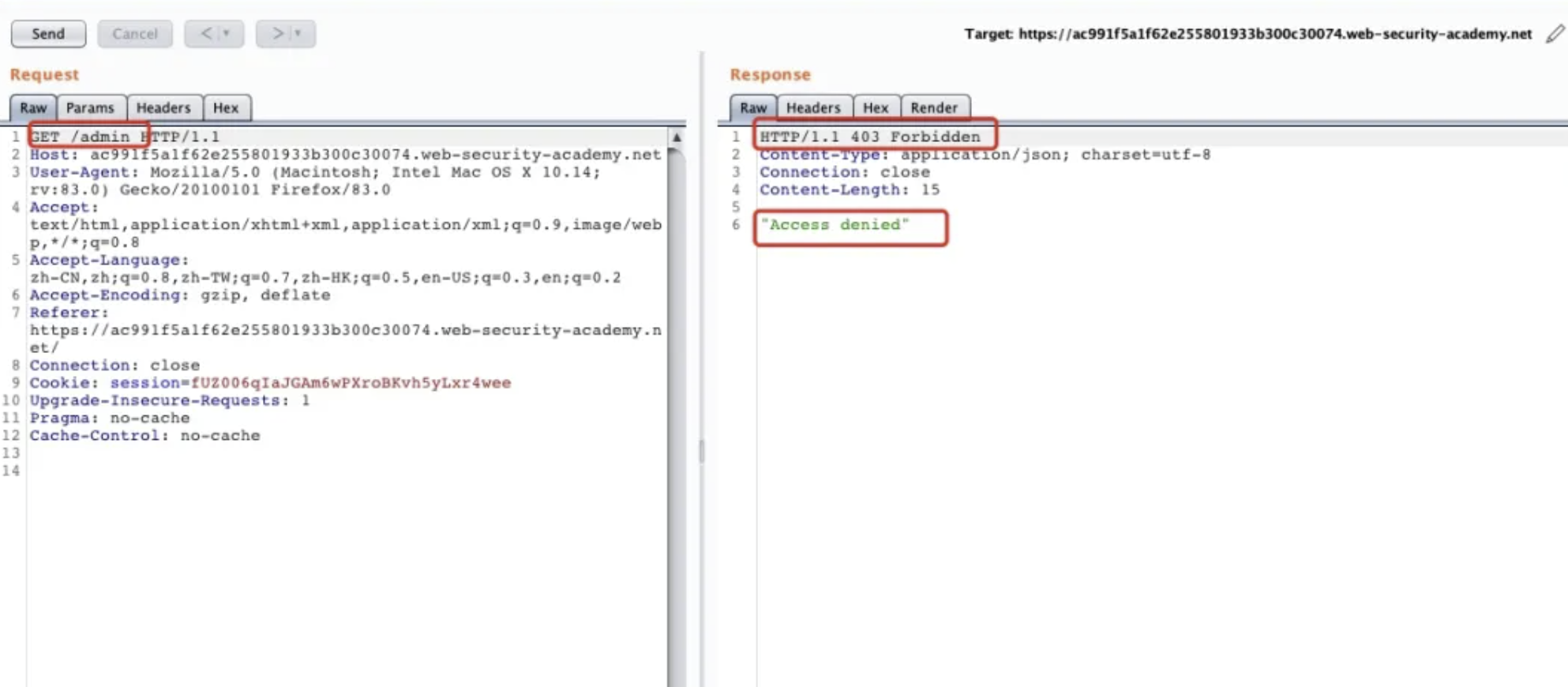
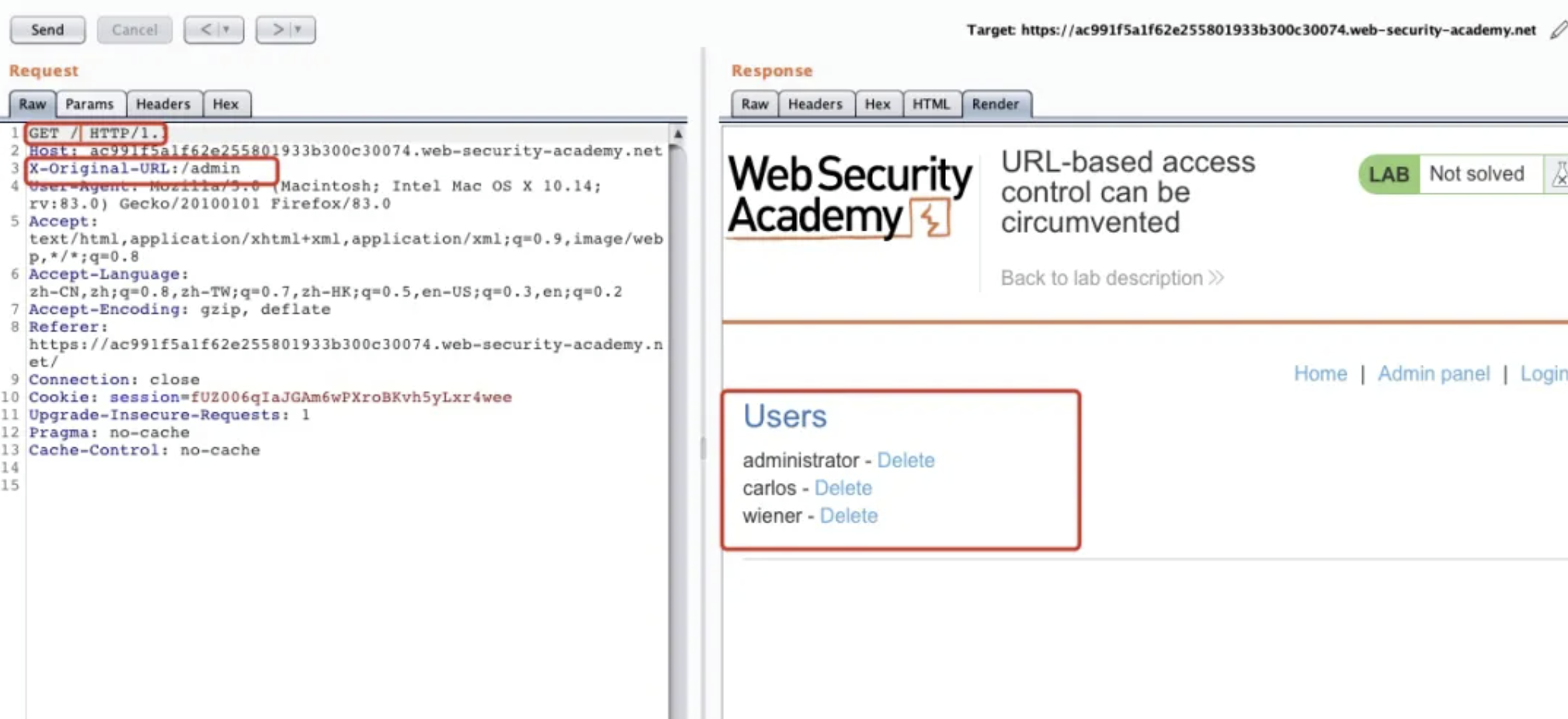
在Header头中添加X-Original-URL标头,发现已经有权限可以删除Administrator、carlos、wiener 帐号的管理员权限
扩展名绕过
1 | site.com/admin => 403 |
绕过案例
某个后台地址 http://www.login.com 只允许工作区的公网出口IP访问,在局域网中,甲方让测试看能不能在外网访问到目标IP
端口绕过
外网进行访问返回403状态码。利用nmap进行全端口探测,发现除了80端口之外,还开放了一个web服务的8001端口,尝试使用8001端口访问(https://www.login.com:8001),总是充满惊喜。可直接绕过IP限制进行访问
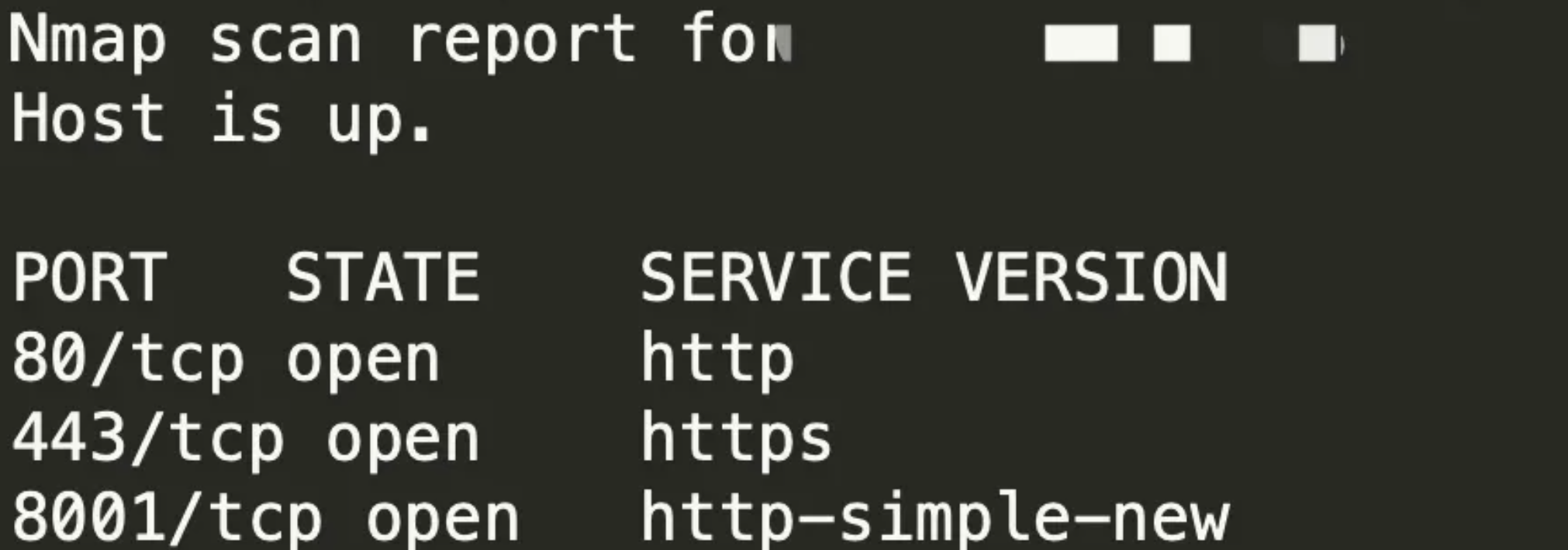
通过沟通,由于疏忽未下线8001端口,导致访问控制缺失,这就是用到了信息收集而已
子域名绕过
外网进行访问返回403状态码
先爆破出一些子域名,再把子域名放在host中去访问
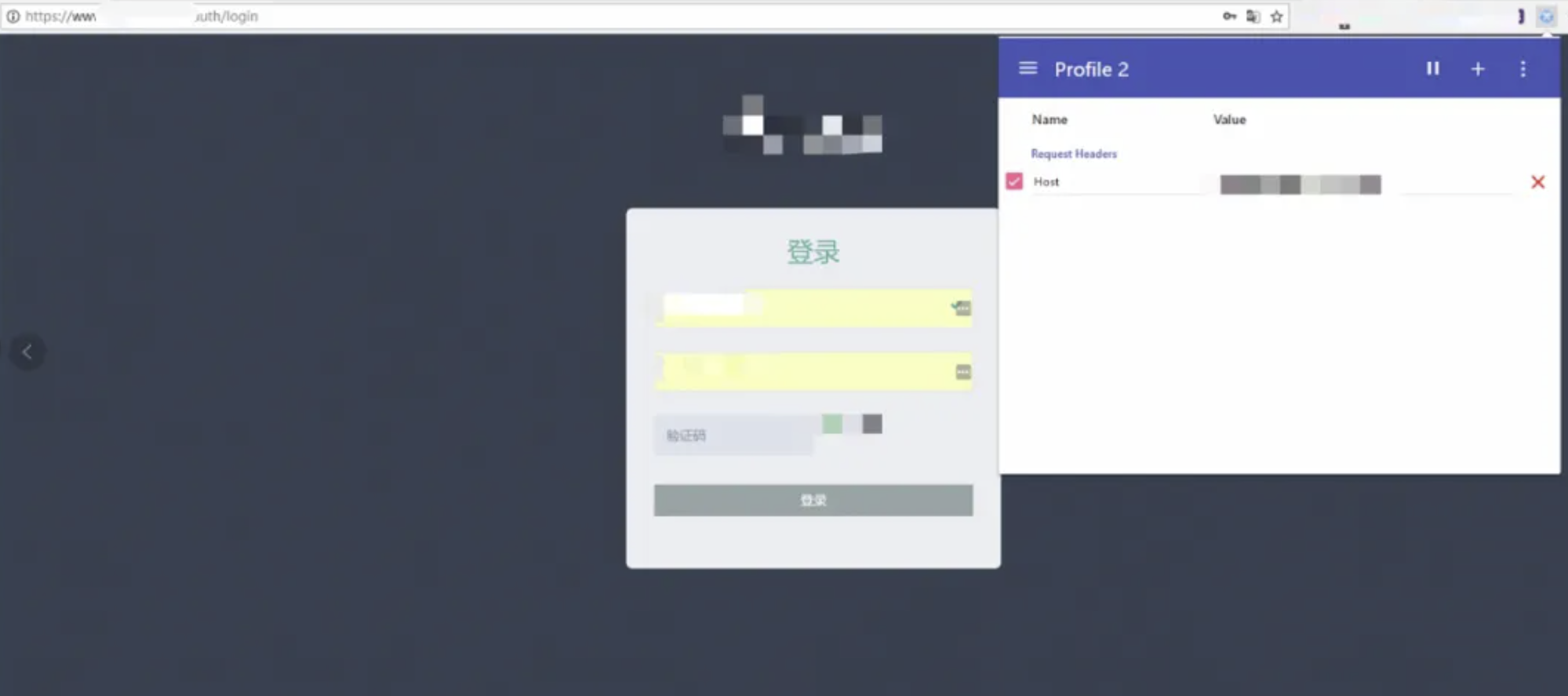
往往成功也离不开运气,看到一个服务端返回200的状态码。成功找到一个在HOST白名单中的子域名,这个子域名没有做好访问控制,这也属于信息收集
工具推荐
https://github.com/sting8k/BurpSuite_403Bypasser
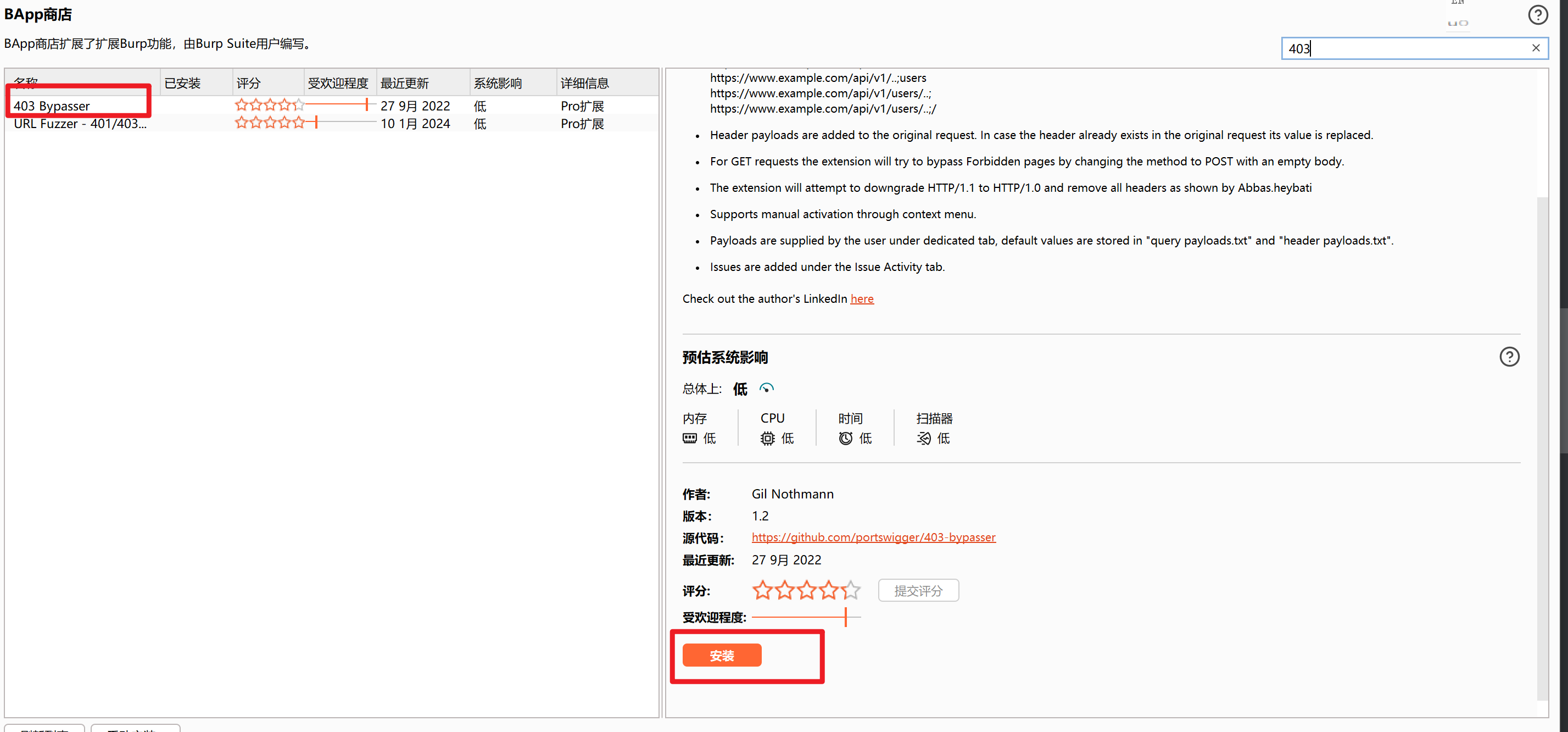
burp插件商店有,需要配置Jython环境
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 X1ly?S!
 联系我
联系我
评论
